Reinforcement Learning (RL) – it’s the buzzword that paints a future of intelligent agents learning to conquer complex tasks, from self-driving cars to sophisticated robotics. But here’s the catch: in the real world, “learning” can sometimes mean “making mistakes,” and those mistakes can be incredibly costly, even dangerous. That’s where Safe Reinforcement Learning (Safe RL) steps in, aiming to teach AI to be smart and responsible.
A survey of Constraint Formulations in Safe Reinforcement Learning
At the heart of Safe Reinforcement Learning lies the crucial concept of constraint formulations. Think of them as the safety rules or guardrails that keep our learning agents from straying into hazardous territory. Without these carefully designed constraints, an RL agent, solely focused on maximizing its rewards, might inadvertently cause damage, violate regulations, or even harm humans.
So, how do we actually tell an AI what’s safe and what’s not? This is where the different “constraint formulations” come into play. Let’s embark on a clear and easy-to-understand journey through the various ways researchers are building these safety nets.
Why Constraints? The Imperative for Safe RL
Imagine training a robotic arm in a factory. If its sole goal is to pick up items as fast as possible, it might swing wildly, potentially hitting workers or damaging machinery. Safe RL, with its constraints, would ensure the arm stays within designated operational zones, maintains safe speeds, and avoids collisions, all while still striving for efficiency.
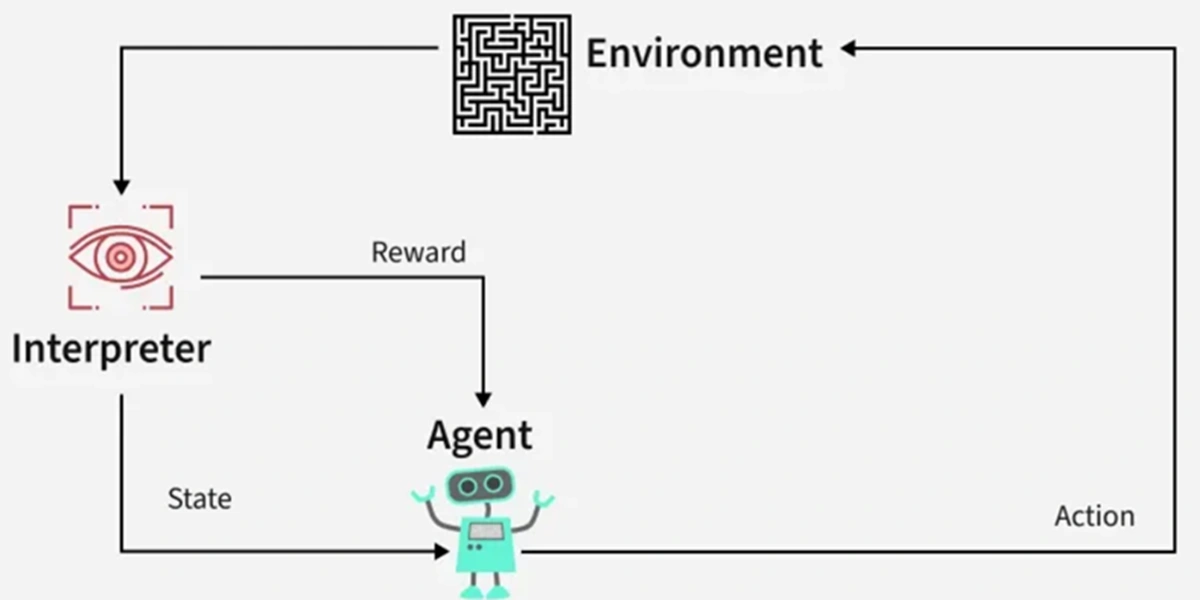
Traditional Reinforcement Learning (RL) algorithms are built on the idea of a Markov Decision Process (MDP), where an agent learns an optimal policy to maximize rewards. Safe RL extends this to a Constrained Markov Decision Process (CMDP), adding explicit safety constraints to the optimization problem.
The Landscape of Constraint Formulations: Keeping AI in Check
The way we define and enforce these safety constraints can vary significantly, each with its own strengths and use cases. Let’s break down some of the most common and impactful formulations:
1. Expected Cumulative Cost Constraints: Playing the Long Game Safely
This is one of the most popular approaches. Here, the safety constraint is framed as limiting the expected total cost (or negative reward) over an entire task or episode.
- How it works: Imagine a self-driving car. An expected cumulative cost constraint might aim to keep the total “risk score” (e.g., from near-misses, speeding, hard braking) below a certain threshold over a journey. The agent learns to drive in a way that minimizes this accumulated safety violation.
- Analogy: It’s like a budget. You have a certain amount of “safety budget” for the entire trip, and the car needs to manage its actions to stay within that budget.
- Pros: Flexible, allows for occasional minor violations if compensated by overall safety.
- Cons: Doesn’t guarantee instantaneous safety. A single catastrophic event could still occur if the “budget” allows it, even if the overall average is safe.
2. Instantaneous Constraints: Safety at Every Step
Sometimes, we need absolute, real-time safety guarantees. Instantaneous constraints ensure that a safety condition holds true at every single moment or time step during the agent’s operation.
- How it works: For that factory robotic arm, an instantaneous constraint would ensure its torque limits are never exceeded, or that it never enters a human’s workspace, even for a split second.
- Analogy: Think of it as a hard red line. You cannot cross it, ever.
- Pros: Provides strong, immediate safety guarantees, crucial for high-stakes applications.
- Cons: Can be overly conservative, potentially limiting the agent’s performance or exploration. It’s harder for the agent to learn if it’s constantly hitting a “no-go” zone.
3. Probabilistic Constraints (Chance Constraints): Managing Risk with Confidence
In many real-world scenarios, perfect guarantees are impossible due to inherent uncertainties (like sensor noise or unpredictable environments). Probabilistic constraints, also known as chance constraints, allow for a small, predefined probability of violating a safety condition.
- How it works: A drone might be constrained to stay within a certain altitude range with a 99.9% probability. This acknowledges that extreme weather or sensor glitches might occasionally cause it to deviate, but keeps the risk incredibly low.
- Analogy: “We’re 99% sure this won’t happen.” It’s about setting an acceptable level of risk.
- Pros: More realistic for uncertain environments, allows for a bit more flexibility than hard instantaneous constraints.
- Cons: Still requires careful definition of acceptable risk levels; might be harder to guarantee true safety in every scenario.
4. Hard vs. Soft Constraints: The Spectrum of Enforcement
Beyond the temporal aspect, constraints can also be categorized by their rigidity:
- Hard Constraints: These are non-negotiable rules. Violation means immediate failure or shutdown. Often enforced through techniques like “shielding,” where a separate safety mechanism intervenes if the RL agent tries to take an unsafe action.
- Soft Constraints: These are more like “penalties” or “preferences.” Violating them incurs a cost, but doesn’t necessarily halt the operation. The agent is incentivized to avoid violations but can still learn to navigate situations where minor infractions are unavoidable.
The Path Forward: Balancing Safety and Performance
The choice of constraint formulation is critical and depends heavily on the specific application and its safety criticality. Researchers are continuously exploring novel ways to:
- Learn constraints: Instead of hand-coding every rule, can AI learn safety boundaries from demonstrations or expert feedback?
- Combine formulations: Can we blend the strengths of instantaneous and cumulative constraints to achieve both immediate safety and long-term optimality?
- Handle uncertainty: How can we design robust constraints that perform well even when faced with unexpected events or noisy data?
The field of Safe Reinforcement Learning is a vibrant and essential area of research. By carefully designing and implementing constraint formulations, we’re not just building smarter AI; we’re building AI we can trust, paving the way for its responsible and impactful deployment in our world. As these techniques evolve, the future of AI looks not only intelligent, but also inherently safe.





