An overloaded functions appears to perform different activities depending on the kind of data sent to it. Overloading is like the joke about the famous scientist who insisted that the thermos bottle was the greatest invention of all time. Why? “It’s a miracle device,” he said. “It keeps hot things hot, but cold things it keeps cold. How does it know?”
It may seem equally mysterious how an overloaded function knows what to do. It performs one operation on one kind of data but another operation on a different kind. Let’s clarify matters with some examples.
Different Numbers of Arguments
Recall the starline() function in the TABLE example and the repchar() function from the TABLEARG example, both shown earlier in this post. The starline() function printed a line using 45 asterisks, while repchar() used a character and a line length that were both specified when the function was called. We might imagine a third function, charline(), that always prints 45 characters but that allows the calling program to specify the character to be printed.
These three functions starline(), repchar(), and charline() perform similar activities but have different names. For programmers using these functions, that means three names to remember and three places to look them up if they are listed alphabetically in an application’s Function Reference documentation.
It would be far more convenient to use the same name for all three functions, even though they each have different arguments. Here’s a program, OVERLOAD, that makes this possible:
// overload.cpp
// demonstrates function overloading
#include <iostream>
using namespace std;
//declarations
void repchar();
void repchar(char);
void repchar(char, int);
int main()
{
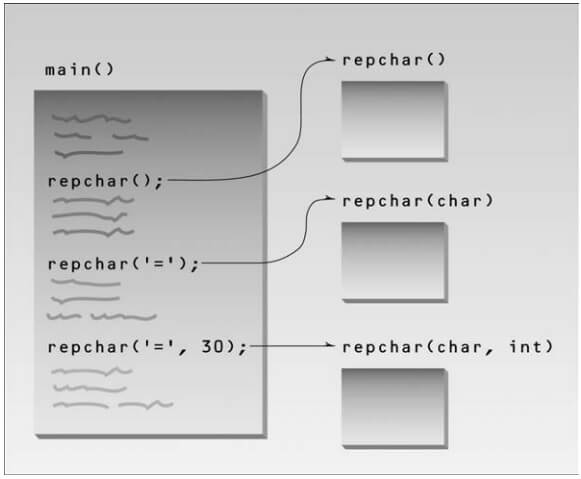
repchar();
repchar(‘=’);
repchar(‘+’, 30);
return 0;
}
//--------------------------------------------------------------
// repchar()
// displays 45 asterisks
void repchar()
{
for(int j=0; j<45; j++) // always loops 45 times
cout << ‘*’; // always prints asterisk
cout << endl;
}
//--------------------------------------------------------------
// repchar()
// displays 45 copies of specified character
void repchar(char ch)
{
for(int j=0; j<45; j++) // always loops 45 times
cout << ch; // prints specified character
cout << endl;
}
//--------------------------------------------------------------
// repchar()
// displays specified number of copies of specified character
void repchar(char ch, int n)
{
for(int j=0; j<n; j++) // loops n times
cout << ch; // prints specified character
cout << endl;
}
This program prints out three lines of characters. Here’s the output:
*********************************************
=============================================
++++++++++++++++++++++++++++++
The first two lines are 45 characters long, and the third is 30.
The program contains three functions with the same name. There are three declarations, three function calls, and three function definitions. What keeps the compiler from becoming hopelessly confused? It uses the function signature the number of arguments, and their data types to distinguish one function from another. In other words, the declaration
void repchar();
which takes no arguments, describes an entirely different function than the declaration
void repchar(char);
which takes one argument of type char, or the declaration
void repchar(char, int);
which takes one argument of type char and another of type int.
The compiler, seeing several functions with the same name but different numbers of arguments, could decide the programmer had made a mistake (which is what it would do in C). Instead, it very tolerantly sets up a separate function for every such definition. Which one of these functions will be called depends on the number of arguments supplied in the call. Figure shows this process.
Different Kinds of Arguments
In the OVERLOAD example we created several functions with the same name but different numbers of arguments. The compiler can also distinguish between overloaded functions with the same number of arguments, provided their type is different. Here’s a program, OVERENGL, that uses an overloaded function to display a quantity in feet-and-inches format. The single argument to the function can be either a structure of type Distance (as used in the ENGLDISP example) or a simple variable of type float. Different functions are used depending on the type of argument.
// overengl.cpp
// demonstrates overloaded functions
#include <iostream>
using namespace std;
////////////////////////////////////////////////////////////////
struct Distance //English distance
{
int feet;
float inches;
};
////////////////////////////////////////////////////////////////
void engldisp( Distance ); //declarations
void engldisp( float );
int main()
{
Distance d1; //distance of type Distance
float d2; //distance of type float
//get length d1 from user
cout << “\nEnter feet: “; cin >> d1.feet;
cout << “Enter inches: “; cin >> d1.inches;
//get length d2 from user
cout << “Enter entire distance in inches: “; cin >> d2;
cout << “\nd1 = “;
engldisp(d1); //display length 1
cout << “\nd2 = “;
engldisp(d2); //display length 2
cout << endl;
return 0;
}
//--------------------------------------------------------------
// engldisp()
// display structure of type Distance in feet and inches
void engldisp( Distance dd ) //parameter dd of type Distance
{
cout << dd.feet << “\’-” << dd.inches << “\””;
}
//--------------------------------------------------------------
// engldisp()
// display variable of type float in feet and inches
void engldisp( float dd ) //parameter dd of type float
{
int feet = static_cast(dd / 12);
float inches = dd - feet*12;
cout << feet << “\’-” << inches << “\””;
}
The user is invited to enter two distances, the first with separate feet and inches inputs, the second with a single large number for inches (109.5 inches, for example, instead of 9’–1.5”). The program calls the overloaded function engldisp() to display a value of type Distance for the first distance and of type float for the second. Here’s some sample interaction with the program
Enter feet: 5 Enter inches: 10.5 Enter entire distance in inches: 76.5 d1 = 5’-10.5” d2 = 6’-4.5”
Notice that, while the different versions of engldisp() do similar things, the code is quite different. The version that accepts the all-inches input has to convert to feet and inches before displaying the result.
Overloaded functions can simplify the programmer’s life by reducing the number of function names to be remembered. As an example of the complexity that arises when overloading is not used, consider the C++ library routines for finding the absolute value of a number. Because these routines must work with C (which does not allow overloading) as well as with C++, there must be separate versions of the absolute value routine for each data type. There are four of them: abs() for type int, cabs() for complex numbers, fabs() for type double, and labs() for type long. In C++, a single name, abs(), would suffice for all these data types.
As we’ll see later, overloaded functions are also useful for handling different types of objects.
| Read More Topics |
| Variables in C |
| Nesting of Function in C |
| Function Declaration in C |
| Passing Arrays to Function in C |





